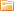

Инженер открывает тренд после ночной смены и видит не аварию, а её предысторию. Сначала едва заметно ползёт вверх вибрация, затем появляется температурный дрейф, потом клапан начинает отрабатывать команду на доли секунды медленнее обычного. В таблице эти изменения выглядят как разрозненные числа. На хорошем графике они складываются в причинно-следственную цепочку.
Именно здесь проходит граница между старой логикой архивирования и тем, что требуется предприятию сейчас. Раньше архив был приложением к SCADA: сохранить данные на несколько месяцев, при необходимости поднять историю, построить простой тренд.
Сегодня архив становится рабочим органом предиктивной аналитики, расследования инцидентов и оптимизации режима. Если он пишет медленно, читает с задержкой или не умеет показывать взаимосвязи между сигналами, то предприятие получает не цифровой контур управления, а просто склад чисел.
Почему старой модели уже недостаточно
Ещё недавно глубина хранения в несколько месяцев при секундном опросе действительно решала большую часть задач. Такой архив помогал оператору понять, что происходило на установке за смену, максимум - за неделю или месяц. Но с приходом Industry 4.0 смысл данных изменился. Теперь важен не сам факт хранения, а возможность работать с длинной историей как с живым материалом для анализа.
Предиктивное обслуживание, цифровые двойники, анализ деградации узлов, поиск неочевидных корреляций между параметрами - всё это требует другого масштаба. Нужна миллисекундная, а иногда и субмиллисекундная детализация. Нужна история не за квартал, а за годы. Нужен не медленный доступ к архиву по запросу, а почти мгновенный вывод массива на экран, чтобы инженер мог сравнить два режима работы без паузы на выгрузку.
Из этого вытекает простая мысль: historian в современной АСУ ТП - это уже не фоновая сервисная функция. Это один из элементов устойчивости производства. Он влияет на то, как быстро будет замечена аномалия, насколько точно удастся восстановить хронологию событий и можно ли вообще перейти от ППР к обслуживанию по фактическому состоянию.
Historian-системы - это специализированные базы данных реального времени для сбора, долгосрочного хранения и анализа огромных объемов производственных данных (временных рядов), генерируемых SCADA и ПЛК. Они объединяют скорость реляционных БД с функциями архивирования, обеспечивая мониторинг процессов, отчетность и диагностику.
Программное обеспечение для ведения истории данных о процессах
Почему хороший тренд окупается быстрее, чем кажется
У визуализации в промышленности есть важное свойство: она показывает не только величину отклонения, но и его характер. Для инженера это принципиально. Рост давления ступенькой и рост давления с колебаниями - это разные истории. Медленный дрейф температуры и резкий тепловой выброс - тоже. Когда несколько параметров наложены друг на друга по времени, картина становится объёмной. Видно, что было первичным событием, а что лишь следствием.
Поэтому качественный тренд - не декоративная функция интерфейса, а инструмент снижения риска. Он ускоряет оперативное решение при появлении аномального поведения, позволяет быстрее локализовать источник проблемы и сокращает время расследования после инцидента.
Когда нужно понять, почему возник брак, почему сработала защита или отчего линия ушла в останов, инженер ищет не абстрактную "ошибку", а последовательность изменений. Хорошая визуализация как раз и восстанавливает эту последовательность.
Есть и второй эффект, менее заметный, но не менее важный. Тренды помогают улучшать не только аварийную, но и штатную работу объекта.
Сравнение графиков за разные смены, рецептуры, партии сырья или наборы настроек ПИД-регуляторов позволяет увидеть, где процесс работает на пределе, где появляется лишняя инерция, а где оборудование уже начинает стареть.
Отсюда рождаются решения о перенастройке контура, модернизации узла или изменении режима эксплуатации. В реальном производстве даже несколько процентов улучшения по качеству или энергоэффективности окупают систему гораздо быстрее, чем принято думать.
Что требуется от historian-системы сейчас
У хорошей historian-системы сегодня четыре обязательных свойства:
- Первое - очень высокая скорость записи. Если поток телеметрии от полевого уровня становится плотнее, архив не должен превращаться в бутылочное горлышко.
- Второе - быстрая выборка. История ценна ровно настолько, насколько быстро её можно превратить в график, таблицу или расчёт.
- Третье - гибкая визуализация: масштабирование, наложение аналоговых и дискретных тегов, синхронный просмотр событий и параметров, сравнение интервалов времени.
- Четвёртое - простая интеграция с SCADA, аналитикой и AI/ML-инструментами.
Технически такие решения всё чаще относятся к классу TSDB - специализированных баз данных временных рядов, оптимизированных под хранение пар "время - значение". Именно под такую логику работы позиционируется и АВАДС Historian, который разработчик относит к классу historian-решений для SCADA и MES-систем.
Для инженера это важно не из-за модного термина, а из-за прикладного результата. Если база изначально строится под временные ряды, она лучше приспособлена к интенсивной записи, длинной истории и быстрому чтению архивов за большие интервалы времени. В публикациях по продукту отдельно подчёркивается, что система рассчитана на высокоскоростные, высоконадёжные и компактные архивы данных реального времени.
Программное обеспечение для ведения истории данных о процессах
Класс historian-систем сформировался в промышленности гораздо раньше, чем появилось само слово TSDB.
Первые серверы процессных архивов появились в конце 1980-х годов как ответ на запросы нефтехимической и энергетической отрасли: SCADA могла отобразить текущее состояние процесса, но не давала инструментов для работы с накопленной историей. Именно тогда OSIsoft выпустила PI System, которая на несколько десятилетий стала отраслевым стандартом.
Следом появились IP.21 от Aspen Technology, PHD от Honeywell, InSQL (позднее - AVEVA Historian) от Wonderware, Proficy Historian от GE Fanuc и ряд других решений. Все они решали одну задачу: принять непрерывный поток значений от тысяч тегов, сохранить его надолго и отдать по запросу быстро.
Принципиальное отличие historian-системы от универсальной реляционной СУБД состоит в структуре данных. Реляционная база хранит записи в таблицах с произвольной схемой, и каждый запрос требует обхода индексов, оптимизированных под транзакции.
Historian хранит пары "время - значение" в последовательно организованных сегментах, где время само является индексом. Это означает, что чтение диапазона значений за несколько часов или лет выполняется как линейное сканирование, а не как поиск по B-дереву.
Именно поэтому специализированные historian-системы при одинаковых объёмах данных читают архивы в десятки раз быстрее, чем PostgreSQL или MS SQL Server.
Архитектурно современные historian-продукты устроены как клиент-серверные системы с несколькими слоями:
- Нижний - интерфейсы сбора: OPC DA, OPC UA, Modbus, собственные API, файловые адаптеры;
- Средний - хранилище: специализированный движок с компрессией данных и управлением глубиной хранения;
- Верхний - клиенты: трендовые инструменты, веб-интерфейсы, REST API и шлюзы в MES, ERP, BI-системы.
Между слоями данные движутся в обоих направлениях - запись идёт сверху вниз от полевого уровня, выборка для аналитики идёт снизу вверх к приложениям.
Отдельную нишу сегодня занимают открытые TSDB-решения - InfluxDB, TimescaleDB, OpenTSDB. Все три изначально создавались не для промышленности, а для мониторинга ИТ-инфраструктуры, и это чувствуется.
InfluxDB, например, блестяще работает с метриками серверов и IoT-данными, поддерживает высокочастотную запись и имеет богатый язык запросов Flux.
Но в контексте АСУ ТП у неё нет готовых интерфейсов для OPC, нет механизмов сжатия данных, характерных для промышленных historian-систем (таких как deadband-фильтрация или swinging door), нет встроенной концепции тега с метаданными.
Интегратору придётся строить всё это самому, что на промышленном объекте почти всегда означает: дешевле взять готовый historian. Тем не менее в облачных архитектурах и гибридных сценариях открытые TSDB активно используются на верхнем уровне - принимая данные уже из промышленного historian-сервера, а не напрямую с полевого уровня.
Среди специфических механизмов, отличающих промышленный historian от любой другой базы данных, особое место занимает компрессия временных рядов.
Самый распространённый алгоритм - swinging door trending (SDT), известный также как алгоритм поворотной двери. Его идея проста: если новое значение укладывается в линейный коридор, построенный через предыдущие точки, оно не сохраняется - вместо него хранится лишь граничная точка тренда. Это позволяет сократить объём архива в 5-20 раз при практически незаметной потере точности для большинства технологических параметров.
В сочетании с правильно настроенным deadband (порогом нечувствительности по значению) такой подход обеспечивает то самое компактное хранение, которое на практике означает разницу между архивом за три года и архивом за двадцать лет на одном и том же носителе.
Рынок historian-решений за последние пять лет заметно расслоился:
- Верхний сегмент - AVEVA PI System (бывший OSIsoft PI), AVEVA Historian (бывший Wonderware InSQL) и Aspentech IP.21 - ориентирован на крупные предприятия с десятками тысяч тегов, корпоративной аналитикой и жёсткими требованиями к нормативному хранению данных;
- Средний сегмент - Proficy Historian (GE), Ignition Historian (Inductive Automation), ряд других продуктов - нацелен на средние производства с несколькими тысячами тегов и более гибкими требованиями к интеграции;
- Нижний сегмент стал наиболее динамичным: здесь появляются новые решения, включая российские разработки, построенные на собственных TSDB-движках и рассчитанные на импортозамещение в условиях ограничений на зарубежное ПО.
Отдельной темой стала связка historian-систем с платформами предиктивной аналитики. Само по себе хранение истории - это лишь предпосылка. Реальная ценность появляется, когда над архивом начинают работать алгоритмы машинного обучения, статистические модели и системы раннего предупреждения.
По данным исследований, предприятия, внедрившие предиктивную аналитику на базе промышленных данных, сокращают количество незапланированных простоев на 30% и снижают затраты на обслуживание на 20-30%.
Для этого historian должен уметь не просто хранить данные, но и отдавать их в виде, пригодном для аналитических платформ. Современные продукты реализуют это через REST API, MQTT-брокеры, интеграцию с Kafka и специализированные коннекторы для Python, MATLAB и аналитических платформ.
Таким образом, historian превращается из изолированного архива в источник данных для всей цифровой экосистемы предприятия - от оперативного мониторинга на уровне SCADA до корпоративных BI-систем и ML-конвейеров верхнего уровня.
Важно понимать, что historian-ПО - это не только про хранение. Это про то, что данные превращаются в ресурс. Когда архив организован правильно, оперативный инженер видит предысторию каждого отклонения, технолог сравнивает режимы за разные кварталы, а алгоритм предиктивного обслуживания получает непрерывную ленту измерений нужного качества и глубины.
Без надёжного historian весь этот контур разрушается: ML-модели деградируют из-за пробелов в данных, расследования инцидентов затягиваются, а предиктивное обслуживание превращается в хорошее намерение без практической реализации.
Андрей Повный